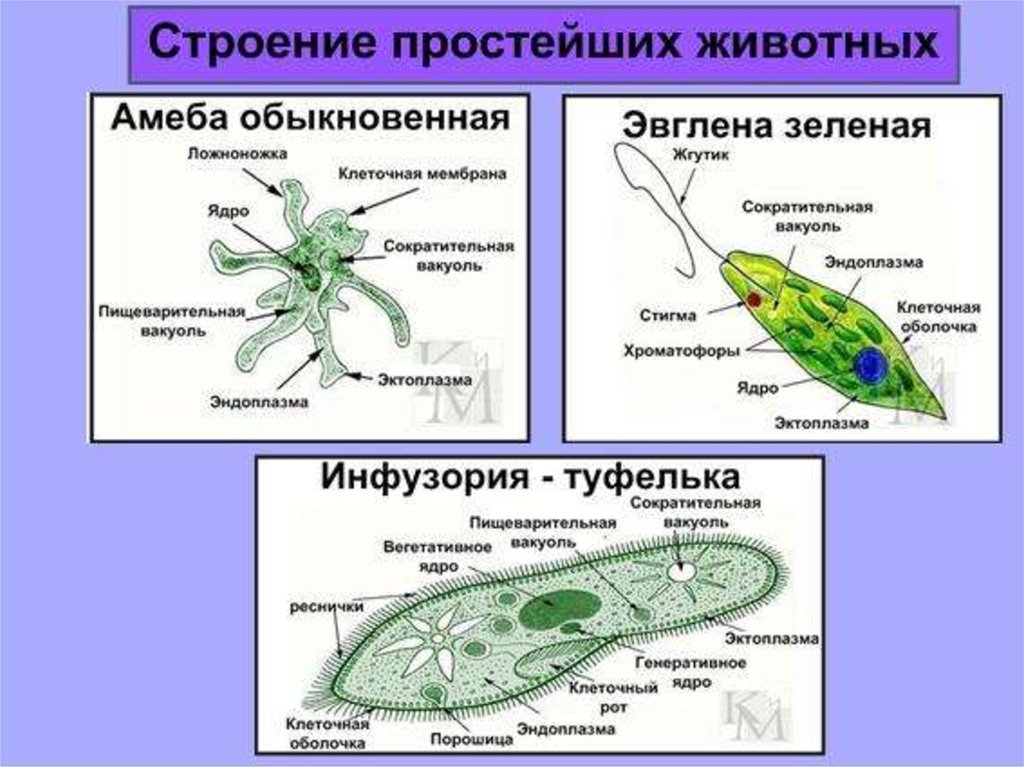
Виды баз данных — реляционные и другие подходы к организации БД в программировании
В этой статье мы рассмотрим основные виды баз данных. На конкретных примерах выявим преимущества и недостатки каждой модели, изучим сценарии их применения.
Что такое база данных
База данных — это набор сведений об объектах, структурированный определенным образом. Обычно базы данных управляются специальным ПО, или системами управления базами данных (СУБД).
В зависимости от вида логическая структура базы данных может иметь различное описание. Это различие влияет на то, какая именно БД используется в разработке конкретного продукта или технологии.
Простейшие типы баз данных
К таким базам данных относятся БД, где хранятся данные с простой структурой: например, список разрешенных IP-адресов для доступа к сети, настройки окружения проекта, список подписчиков на рассылку компании и прочее. Они все еще широко распространены.
Текстовые файлы
Информация об объектах собирается в простых по структуре файлах различных форматов – txt, csv и др. Для разделения полей применяются пробелы, табуляция, запятые, точка с запятой и двоеточие.
Для разделения полей применяются пробелы, табуляция, запятые, точка с запятой и двоеточие.
Примеры: etc/passwd и etc/fstab в Unix-подобных системах, csv-файлы, ini-файлы и др.
Особенности:
- Просто использовать. Для работы с файлами достаточно примитивного текстового редактора.
- Удобно работать с конфигурационными данными приложений (учетные данные, настройки подключения к удаленным серверам и устройствам, порты и пр.).
Ограничения:
- Сложно установить связи между компонентами данных.
- Не для всех типов информации.
Иерархические базы данных
В отличие от текстовых файлов здесь между хранимыми объектами устанавливаются связи. Объекты делятся на родителей (основные классы или категории объектов) и потомков (экземпляры этих классов или категорий). При этом у каждого потомка может быть не более одного родителя.
Пример иерархической базы данных.Графическим представлением такой базы данных является древовидная структура.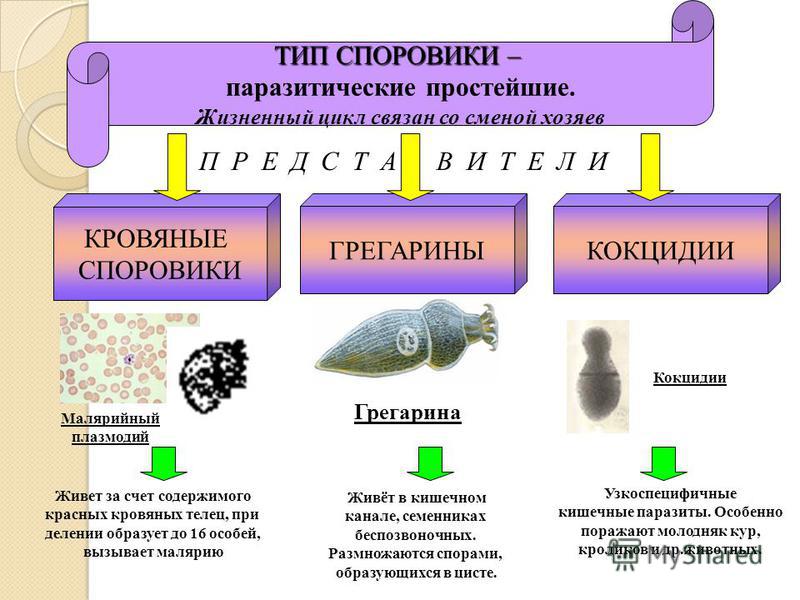
Примеры: Организация файловых систем; DNS и LDAP-соединения.
Особенности:
- Отношения между объектами реализованы в виде физических указателей. Например, в файловой системе путь к папке или файлу строится из имен корневых и вложенных каталогов;
- Моделирование отношений вложенности и подчиненности.
Ограничения: Технология иерархической организации не предполагает связи «многие-ко-многим», а значит, система хранения данных довольно ограничена.
Сетевые базы данных
Эта технология развивает иерархический подход за счет моделирования сложных отношений между объектами. Здесь потомки могут иметь более одного родителя, однако ограничения иерархического подхода сохраняются.
Пример сетевой базы данных.Пример: IDMS — специализированная СУБД для мейнфреймов.
Реляционные базы данных
Данный тип БД является старейшим: теоретические основы подхода заложены британским ученым Эдгаром Коддом в 1970 году.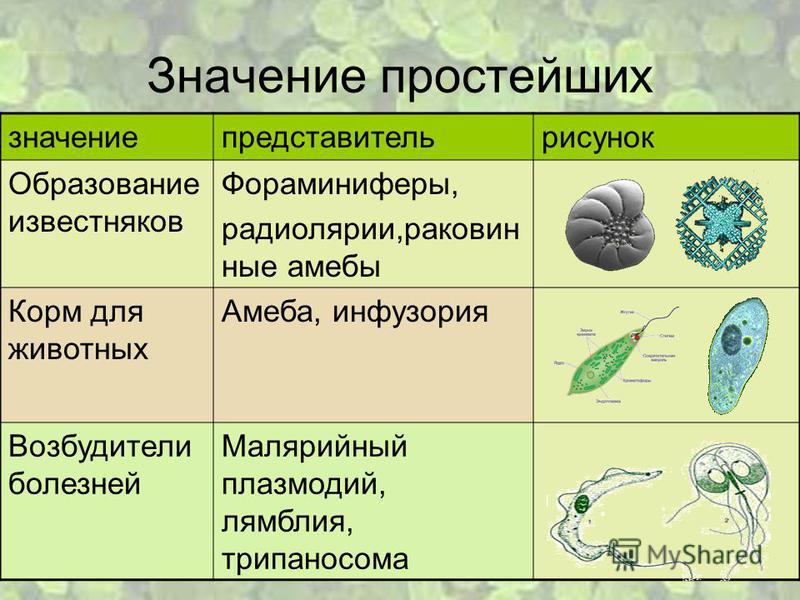 Здесь данные формируются в таблицы из строк и столбцов. В строках приводятся сведения об объектах (значения свойств), а в столбцах — сами свойства объектов (поля).
Здесь данные формируются в таблицы из строк и столбцов. В строках приводятся сведения об объектах (значения свойств), а в столбцах — сами свойства объектов (поля).
Нормализация
Сложные взаимоотношения объектов в реляционных БД моделируются с помощью внешних ключей – ссылок на другие таблицы. Это позволяет подходить к вопросу проектирования базы данных с позиций нормализации – минимизации избыточности при описании свойств объектов.
Например, если речь идет о меню ресторана, то у каждого блюда есть вес, цена, наименование, калорийность и категория, к которой оно относится — горячие закуски, холодные закуски, первые блюда, десерты, салаты и так далее. Связь между блюдами и категорией выполняется посредством ссылочного поля индекса категории в таблице блюд.
Такой подход позволяет:
- Минимизировать объем базы данных: не нужно каждому блюду прописывать название категории.
- Повысить целостность системы: в указанном примере все блюда привязаны к категориям меню.
 Добавление блюда без категории невозможно, равно как и указание в качестве ссылки индекса несуществующей категории.
Добавление блюда без категории невозможно, равно как и указание в качестве ссылки индекса несуществующей категории. - Упростить масштабирование: новые блюда могут быть добавлены в существующие категории. Также не исключается добавление новых категорий, привязка новых блюд к ним и перераспределение блюд по категориям.
- Повысить отказоустойчивость: за счет оптимальной организации схемы таблиц запросы на выборку и агрегацию будут работать с меньшим объемом данных, а значит, быстрее, чем без нормализации. При увеличении числа записей в таблицах со временем это позволит поддерживать положительный пользовательский опыт.
Наглядный пример моделирования сложных взаимоотношений в реляционных БД приведен на рисунке выше. Здесь мы видим модель базы данных учебного заведения, где есть следующие объекты: ученик, курс, преподаватель, отдел, направление обучения.
Связь преподавателя с отделом организована через секцию и курс (внешние ключи id курса и id преподавателя в таблице Секция, а также Отдел в таблице Курс).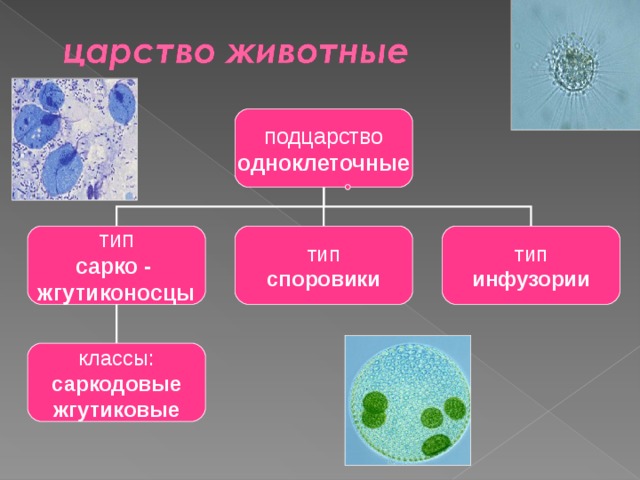 Связь ученика с направлением обучения реализована через таблицу Направление обучения студента (внешние ключи id студента и id направления обучения).
Связь ученика с направлением обучения реализована через таблицу Направление обучения студента (внешние ключи id студента и id направления обучения).
Таким образом, чтобы посчитать, например, количество студентов на курсе и детализировать статистику по преподавателям, необходимо написать запрос с присоединением учеников к направлению, курсу и преподавателям, сделав соответствующую группировку по преподавателям.
Язык запросов SQL
Запросы в реляционных базах данных формируют с помощью структурированного языка SQL. Его предложения позволяют:
- делать выборки,
- проводить агрегации и группировки,
- изменять и удалять данные,
- модифицировать структуру БД (создавать таблицы, поля),
- управлять доступом пользователей к тем или иным операциям и пр.
Денормализация
Помимо нормализации, в реляционных БД существует и обратный процесс — денормализация. Он направлен на перенос наиболее часто используемых полей из внешних таблиц во внутренние. Рассмотрим это на примере мессенджера.
Рассмотрим это на примере мессенджера.
Пользователь (user) оставляет сообщения (messages) в чатах (chat). Структура данных такова, что сообщения связаны с пользователем и чатом через внешние ключи (user_from и user_to, а также chat_id в таблице сообщений; user_id и chat_id в таблице user_chat_link). Поскольку схема нормализована, то различные запросы на выборку, подсчет и агрегацию статистики по чатам, пользователям и сообщениям необходимо выполнять с помощью присоединения внешних таблиц.
На относительно небольших объемах данных эти запросы будут отрабатывать быстро, а с увеличением размера базы – замедляться. Причина кроется в механизме присоединения. Он основан на построчном сравнении двух и более таблиц по условию соединения — например, равенство chat_id в messages и id в chat. А это дает нагрузку на сервер базы данных, которая с ростом ее размера только увеличивается. Для оптимизации такого рода запросов и существует механизм денормализации.
В таблицу связи пользователя и чата user_chat_link добавлены дублирующие поля имени чата (chat_name) и аватара (chat_logo). Также туда выводятся последнее сообщение (last_msg) и количество непрочитанных сообщений (unread_msg_count).
Также туда выводятся последнее сообщение (last_msg) и количество непрочитанных сообщений (unread_msg_count).
Теперь для получения указанных выше полей и проведения аналитики по ним можно использовать таблицу user_chat_link без необходимости соединения с таблицей сообщений. Тем не менее, такой подход имеет ограничения.
За счет дополнительных полей оптимизируются запросы на чтение и агрегацию данных, однако ценой этого является вынужденная избыточность и усложнение бизнес-логики приложения. В частности, усложняется написание запросов изменения данных (update и delete), а также модификации структуры базы (create).
Использование денормализации должно быть тщательно осмыслено. Нужно быть уверенным в том, что нормализованная структура, оптимизированные запросы и правильно настроенные индексы более не способны удовлетворять критерию быстродействия.
Преимущества реляционного подхода:
- определение сложных отношений между объектами,
- нормализация и денормализация данных,
- структурированный язык запросов,
- богатая история развития и широкое распространение (основной инструмент при разработке различных приложений и сервисов).

Недостатки подхода: жесткая структура сведений об объектах.
Примеры: MySQL, MariaDB, PostgreSQL, SQLite и др.
NoSQL и нереляционные базы данных
Все преимущества и недостатки реляционных БД основаны на жесткой структуризации и типизации сведений об объектах. С одной стороны, можно оптимизировать хранение и индексирование данных за счет нормализации или же денормализации. С другой — сложно организовать хранение и обработку плохо структурированных (например, объекты кэша) или вовсе не структурированных данных (например, данные из нескольких источников).
Для борьбы с этими ограничениями было разработано семейство нереляционных БД. Рассмотрим их подробнее.
Базы данных «Ключ-значение»
Это простейшая разновидность нереляционных БД. Данные хранятся в виде словаря, где указателем выступает ключ.
Особенности:
- Хранение и обработка разных по типу и содержанию данных: в одном хранилище под разными ключами могут находиться файлы, строки, текст, числа, JSON-объекты и другие типы данных.

- Высокая скорость доступа к данным за счет адресного хранения.
- Легкое масштабирование. Можно создать правила шардирования по определенным ключам – например, сессии пользователей разных сайтов хранятся в различных сегментах БД.
Ограничения: Поскольку подход не предполагает жесткой типизации и структуризации данных, то контроль их валидности, а также нейминг ключей отдаются на откуп разработчику.
Примеры: Amazon, DynamoDB, Redis, Riak, LevelDB, различные хранилища кэша – например, Memcached и пр.
Документоориентированные БД
В отличие от баз типа «Ключ-значение» данные здесь хранятся в структурированных форматах – XML, JSON, BSON. Тем не менее, сохраняется адресный доступ к данным по ключу. При этом содержимое документа может иметь различный набор свойств.
Например, каталог профилей пользователей: один в качестве предпочтений указал любимое блюдо, а другой – видеоигру. Поскольку эти сведения нельзя хранить в одном поле ввиду логической и структурной разобщенности, они записываются в отдельные свойства отдельных документов. При необходимости можно добавить в документы новые свойства, не нарушив при этом общей целостности данных.
При необходимости можно добавить в документы новые свойства, не нарушив при этом общей целостности данных.
Особенности:
- хорошо подходят для быстрой разработки систем и сервисов, работающих с по-разному структурированными данными,
- легко масштабируются и меняют структуру при необходимости.
Примеры: MongoDB, RethinkDB, CouchDB, DocumentDB.
Графовые базы данных
Это семейство баз предназначено для моделирования сложных отношений с помощью теории графов, где связями выступают ребра графа, а сами объекты – это узлы или вершины.
Пример структуры графовой базы данных.Такой подход может пригодиться при анализе профилей пользователей социальных сетей. Один пользователь подписан на обновления второго, другой пользователь подписан на определенное сообщество и так далее. Также технология может использоваться при анализе экономической активности контрагентов для выявления различных схем мошенничества. Например, можно отследить использование определенных счетов, карт или реквизитов контрагентов в различных операциях.
Особенности: высокая производительность, поскольку обход ребер и вершин значительно быстрее анализа множества внешних и внутренних таблиц и их соединения по условию отбора в реляционных БД.
Примеры: Neo4J, JanusGraph, Dgraph, OrientDB.
Колоночные базы данных
Как можно понять из названия, записи в таких базах хранятся не по строкам, а по столбцам (колонкам). Вместо таблиц здесь используются колоночные семейства. Они содержат ключи, указывающие на формат строки записи информации об объекте. Каждая строка имеет свой набор свойств, что позволяет хранить в рамках одного семейства разно структурированные данные.
Технология активно используется при построении аналитических систем и сервисов, работающих с большими объемами данных.
На рисунке приведен пример колоночного хранения информации о фруктах. Известно три типа фруктов: яблоки, виноград, бананы. Все они объединены в семейство фруктов.
У каждого фрукта индивидуальный набор свойств. Для яблок это цвет, цена и наличие. У винограда это цвет, цена, число ягод в связке и происхождение (импортный или нет). У бананов же это цвет, цена, число в связке и зрелость.
Для яблок это цвет, цена и наличие. У винограда это цвет, цена, число ягод в связке и происхождение (импортный или нет). У бананов же это цвет, цена, число в связке и зрелость.
Чтобы получить детальную сводку по одному типу фруктов, достаточно в запросе указать его идентификатор. При этом можно построить аналитический запрос по общим для всего семейства признакам – например, посчитать число фруктов с группировкой по цвету, вычислить среднюю цену на все фрукты в магазине и т.д.
Особенности:
- С группировкой свойств по колонкам при запросе индексируется меньший объем данных, что обеспечивает высокую скорость его выполнения.
- Широкие возможности масштабирования и модификации структуры — так, при добавлении новых колонок не придется их жестко формализовывать, как в случае с реляционными базами.
Примеры: Cassandra, HBase, ClickHouse.
Базы данных временных рядов
Данный тип БД можно использовать при необходимости отслеживания исторической динамики по ряду показателей. Здесь данные группируются по временным меткам. Базы временных рядом чаще ориентированы на запись, чем на построение сложных аналитических запросов.
Здесь данные группируются по временным меткам. Базы временных рядом чаще ориентированы на запись, чем на построение сложных аналитических запросов.
На рисунке выше приведен пример использования такой БД для отслеживания состояния ПК во времени по ряду показателей – температуре процессора, загрузке системы и потреблению оперативной памяти.
Особенности: Можно обрабатывать постоянный поток входных данных.
Ограничения: Производительность зависит от объема поступающей информации, количества отслеживаемых метрик, а также временного лага между записью новых данных и запросами на чтение
Примеры БД: OpenTSDB, Prometheus, InfluxDB, TimescaleDB
Комбинированные базы
Эта разновидность баз совмещает в себе SQL- и NoSQL-подходы к организации хранения и обработки данных. Этот класс баз включает в себя NewSQL и многомодельные решения. Рассмотрим их подробнее.
Базы данных NewSQL
Данный тип решений для хранения информации стремится обеспечить компромисс между масштабируемостью и согласованностью при сохранении реляционного подхода.
Термин предложил в 2011 году аналитик компании 451 Group Мэтью Аслет. Он отмечал высокую потребность в таких системах для сфер, работающих с критическими данными, — здравоохранение, FinTech и пр. Характерными признаками этих решений являются: использование алгоритмов обеспечения консенсуса (алгоритм Paxos, Raft и др.), шардирование и заточка под горизонтальное масштабирование.
Особенности:
- широкие возможности масштабирования,
- высокая производительность и доступность данных.
Ограничения: Высокие требования к аппаратным ресурсам разработчиков. Но если разрабатываемый продукт является высоконагруженной системой, то применение такой БД имеет смысл.
Примеры баз такого типа: MemSQL, VoltDB, Spanner и др.
Многомодельные базы
Такие БД сочетают в себе несколько подходов к организации данных одновременно. Это обеспечивает функциональное разнообразие при разработке систем с их использованием.
Особенности:
- возможность в одном запросе работать с данными, хранящимися в разных типах баз, не нарушая при этом согласованности;
- обширные возможности масштабирования за счет легкой интеграции новых моделей баз данных в существующую инфраструктуру проекта.
Пример решения данного типа: ArangoDB.
Базы данных в Selectel
В Selectel вы можете запустить готовые облачные базы данных — поддерживаем такие СУБД, как PostgreSQL (в том числе для 1С:Предприятие), MySQL, Redis, TimescaleDB.
Облачные базы данных позволяют исключить работу с инфраструктурой: поднять нужное количество нод можно за несколько минут в панели управления компании. Решение отказоустойчивое и легко масштабируется. На экстренный случай создаются резервные копии для отката состояния базы на срок до семи дней.
Большинство рутинных операций по системному администрированию (настройка, конфигурация, обслуживание и обеспечение безопасности) выполняются специалистами Selectel.
→ Как начать работу с облачными базами данных
Запустите свою базу данных в облаке
Быстрое развертывание самых популярных реляционных и NoSQl-баз данных.
Подробнее
Заключение
В данной статье мы рассмотрели 11 видов баз данных. Каждый имеет свои особенности и ограничения. Решение о выборе того или иного вида необходимо принимать с учетом:
- сложности хранимых данных и взаимосвязей между ними,
- производительности операций чтения/записи и модификации структуры БД на планируемом объеме данных,
- опыта команды разработки,
- стадии жизненного цикла разрабатываемого продукта (производите ли вы доработку действующего решения либо создаете что-то принципиально новое, каковы ваши текущие и перспективные ресурсные возможности).
Автор: Роман Андреев.
Оператор With…End With — Visual Basic
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 3 мин
Выполняет последовательность операторов, которые многократно ссылаются на единственный объект или структуру, чтобы операторы могли использовать упрощенный синтаксис доступ к членам объекта или структуры. При использовании структуры можно только считывать значения членов или вызвать методы. При попытке присвоения значений членам структуры, используемым в операторе
При использовании структуры можно только считывать значения членов или вызвать методы. При попытке присвоения значений членам структуры, используемым в операторе With...End With, возникает ошибка.
Синтаксис
With objectExpression
[ statements ]
End With
Компоненты
| Термин | Определение |
|---|---|
objectExpression | Обязательный. Выражение, результатом которого является объект. Выражение может быть произвольно сложным и вычисляется только один раз. Результатом выражения могут быть данные любого типа, включая простейшие типы. |
statements | Необязательный элемент. Один или несколько операторов между With и End With, которые могут ссылаться на члены объекта, создаваемого при вычислении выражения objectExpression. |
End With | Обязательный. Завершает определение блока With. |
С помощью With...End With можно выполнять последовательность операторов с указанным объектом без необходимости многократного указания имени объекта. В блоке операторов With члены объекта можно указывать начиная с точки, как если бы перед ней стоял объект оператора With.
Например, чтобы изменить несколько свойств одного объекта, поместите операторы присваивания свойств внутрь блока
Если код обращается к одному и тому же объекту в нескольких операторах, оператор With обеспечивает следующие преимущества:
Не требуется многократно вычислять сложное выражение или присваивать результат временной переменной, чтобы несколько раз сослаться на членов объекта.
За счет исключения повторяющихся определяющих выражений код становится более понятным.
Тип данных у objectExpression может быть любым типом класса или структуры или даже простейшим типом Visual Basic (например Integer). При результат вычисления выражения
При результат вычисления выражения objectExpression не является объектом, можно только считывать значения его членов или вызвать методы. При попытке присвоения значений членам структуры, используемым в операторе With...End With, возникает ошибка. Это та же самая ошибка, которая возникает, если сразу после вызова метода, возвращающего структуру, попытаться обратиться к члену результата функции и присвоить ему значение, например GetAPoint().x = 1. Проблема в обоих случаях заключается в том, что структура существует только в стеке вызовов, и в таких ситуациях измененный элемент структуры не может записываться в расположение, чтобы любой другой код в программе может наблюдать за изменением.
Выражение objectExpression вычисляется один раз при входе в блок. Переназначение выражения objectExpression изнутри блока With невозможно.
Внутри блока With к методам и свойствам только указанного объекта можно обращаться без их полного описания.
Оператор With...End With можно разместить внутри другого такого оператора. Вложенные операторы With...End With могут быть сложны для понимания, если указываемые объекты не очевидны из контекста. Необходимо указывать полную ссылку на объект, находящийся во внешнем блоке With, при ссылке на него из внутреннего блока With.
Переходы внутрь блока операторов With из другой части программы запрещены.
Если блок не содержит цикла, операторы выполняются только один раз. Возможно вложение структур управления различных типов. Дополнительные сведения см. в разделе «Вложенные структуры управления».
Примечание
Ключевое слово With можно также использовать в инициализаторах объектов. Дополнительные сведения и примеры см. в разделе » Инициализаторы объектов: именованные и анонимные типы » и «Анонимные типы».
Если блок With используется исключительно для инициализации свойств или полей только что созданного экземпляра объекта, рекомендуется использовать для этой цели инициализатор объекта.
Пример 1
В следующем примере в каждом блоке With выполняется несколько операторов для одного объекта.
Private Sub AddCustomer()
Dim theCustomer As New Customer
With theCustomer
.Name = "Coho Vineyard"
.URL = "http://www.cohovineyard.com/"
.City = "Redmond"
End With
With theCustomer.Comments
.Add("First comment.")
.Add("Second comment.")
End With
End Sub
Public Class Customer
Public Property Name As String
Public Property City As String
Public Property URL As String
Public Property Comments As New List(Of String)
End Class
Пример 2
В следующем примере показаны вложенные операторы With…End With: Во вложенном операторе With этот синтаксис относится к внутреннему объекту.
Dim theWindow As New EntryWindow
With theWindow
With .InfoLabel
.Content = "This is a message."
.Foreground = Brushes.DarkSeaGreen
.Background = Brushes.LightYellow
End With
.Title = "The Form Title"
.Show()
End With
См. также раздел
- List<T>
- Вложенные структуры управления
- Инициализаторы объектов: именованные и анонимные типы
- Анонимные типы
Один из простейших типов сетей
Задача с неполной информацией
Представьте, что я попросил вас сгенерировать неориентированную сеть, содержащую 1000 узлов и примерно 1% возможных ребер. Очевидно, что этих инструкций недостаточно, чтобы точно определить, какой тип сети мне нужен, поскольку я дал вам так мало информации. Но представьте, что вы не могли больше общаться со мной и вам нужно было построить график, не задавая мне никаких уточняющих вопросов.
Придумывая метод построения графика, ваш мыслительный процесс может выглядеть примерно так. Поскольку вам ничего не говорили об обратном, вы могли бы также предположить, что все узлы и ребра идентичны. Также разумно не разрешать соединения узла с самим собой (или множественные соединения между парами узлов). Это означает, что всего имеется $$\binom{1000}{2} = 1000 \cdot 999/2 = 499 500$$ возможных ребер в графе. Чтобы указать сеть по вашей инструкции, вам нужно просто выбрать, какой 1% ребер включить в сеть, т.е. вы должны выбрать 4,995 ребер.
Поскольку вы не знаете, какой 1% соединений включить в сеть, вы можете выбрать их случайным образом. Во-первых, вы пишете компьютерную программу, которая примерно генерирует случайную величину $X$ так, чтобы $X=1$ с вероятностью 1% и $X=0$ в противном случае. Затем вы пишете компьютерную программу, которая проходит через каждое из возможных 499 500 ребер и генерирует экземпляр $X$ для каждого. Например, для ребра между узлами $i$ и $j$ можно вызвать соответствующую случайную переменную $X_{ij}$. Затем компьютер выбирает ребро между узлами $i$ и $j$ для включения в сеть, если $X_{ij}=1$; если $X_{ij}=0$, ребро не включается. При запуске программы вы получаете сеть с 4965 ребер, что составляет около 0,994% возможных ребер. Вы считаете, что это достаточно близко к 1%, и решаете использовать результат для своей сети.
Затем компьютер выбирает ребро между узлами $i$ и $j$ для включения в сеть, если $X_{ij}=1$; если $X_{ij}=0$, ребро не включается. При запуске программы вы получаете сеть с 4965 ребер, что составляет около 0,994% возможных ребер. Вы считаете, что это достаточно близко к 1%, и решаете использовать результат для своей сети.
Результирующая сеть
Сеть какого типа вы создали с помощью своей компьютерной программы? Возможно, вы не задумывались об этом, но сделали одно важное (и естественное) предположение, когда строили график. Когда вы сгенерировали 499 500 случайных $X$, компьютерная программа не позволила результирующему значению одной переменной, скажем, $X_{ij}$, повлиять на вероятность другой переменной, скажем, $X_{kl}$ (для разных узлы $k$ и $l$). Независимо от того, какие значения были выбраны для других $X$, каждый $X_{ij}$ был выбран равным 1 с вероятностью 0,01. Другими словами, компьютерная программа сгенерировала каждое из 9 значений $X$.0013 независимо .
Этот подход был не единственным вариантом. Вы могли бы ввести зависимости между случайными величинами. Например, вы могли бы увеличить или уменьшить вероятность того, что $X_{ij}=1$, в зависимости от того, сколько соединений уже имеют узлы $i$ и $j$ (каким-то образом компенсируя общее количество соединений). вы получите около 1% возможных соединений). Или можно было вообще не использовать случайные величины и, пронумеровав узлы от 1 до 1000, соединить каждый узел с 10 узлами с ближайшими номерами. Если бы у вас было много времени на эту задачу, я уверен, что вы могли бы придумать какую-нибудь замысловатую схему, чтобы придать сети очень сложную структуру.
Минимизация структуры
Созданная вами сеть с независимыми случайными $X$ находится в некоторой оптимальности с учетом полученной вами информации. Оказывается, сеть, в которой ребра выбираются независимо с вероятностью 0,01, имеет наименьшую структуру из всех вариантов, которые вы могли выбрать. Это отсутствие структуры можно количественно определить с помощью энтропии распределения вероятностей, описывающего случайную сеть.
Сгенерированная вами сеть является примером случайной сети Эрдёша-Реньи 1 (или случайной сети ER ), простейшего типа случайной сети. Поскольку все ребра независимы, случайные сети ER являются естественным типом сети, который следует предположить, когда речь идет о случайных сетях. По этой причине люди часто называют ER-случайные сети просто «случайными сетями» и могут рассматривать отклонения от модели Эрдёша-Реньи как «неслучайность». корреляции между ними (хотя такие графики имеют меньшую энтропию, как видно из рамки выше).
Одним из важных следствий независимой генерации ребер является то, что распределение степеней сети является довольно плотным. Вы можете думать о независимости между ребрами как о том, что ребра не могут взаимодействовать друг с другом, когда они генерируются. Когда сеть была сгенерирована, краям не разрешалось вступать в сговор и соглашаться концентрироваться вокруг нескольких узлов и превращать их в концентраторы. Вместо этого независимые ребра в конечном итоге довольно равномерно распределяются по узлам, а распределение степеней является биномиальным распределением. В результате в созданной вами сети степень большинства нейронов была довольно близка к средней степени 10, как показано ниже.
2.1: Простейший тип дифференциального уравнения
- Последнее обновление
- Сохранить как PDF
- Идентификатор страницы
- 90399
- Джеффри Р.
 2.\]
2.\]Например, предположим, что мы сбросили мяч с крыши \(50\) метрового здания. Через какое время мяч упадет на землю? Этот вопрос требует решения \(\eqref{eq:1}\) для времени \(T\), которое требуется для \(x(T) = 0\), учитывая \(x_0 = 50\) метр и \( v_0 = 0\). Решение для \(T\), \[\begin{align}T&=\sqrt{\frac{2x_0}{g}} \\ &=\sqrt{\frac{2\cdot 50}{9.8}}\text {сек} \\ &\ок. 3,2\текст{сек}\конец{выровнено}\]
Эта страница под названием 2.1: The Simplest Type of Differential Equation распространяется под лицензией CC BY 3.0 и была создана, изменена и/или курирована Джеффри Р. Часновым с использованием исходного контента, который был отредактирован в соответствии со стилем и стандартами LibreTexts. Платформа; подробная история редактирования доступна по запросу.
- Наверх
- Была ли эта статья полезной?
- Тип изделия
- Раздел или страница
- Автор
- Джеффри Р.