Какие бывают механизмы для мебели-трансформер?
20.07.2023
Юлия
Мы хотели поблагодарить компанию мебель холл за крутой проект кровати-трансформера с полками + диван! Все было на высшем уровне, начиная с дизайна и заканчивая установкой, все наши пожелания и сроки были…
Читать весь отзыв05.07.2023
Анастасия
Давно хотела приобрести в комнату мебель, которая отвечала бы всем моим запросам: цена, качество ткани (дома есть коты), конструкция (комната небольшая, но хотелось все сделать компактно и функционально)….
Читать весь отзыв28. 06.2023
06.2023
Анастасия
Огромное спасибо команде @zym-mebel. Я в большом восторге от этого проекта. Очень незаменимая вещь, когда хочется спать на кровати и иметь функциональную гостиную. Красиво и эффектно, однозначно на г…
Читать весь отзыв24.03.2023
Евгений Сергеевич
Мне уделили очень много времени. Порой даже было неловко по этому поводу. Все подсказали, рассказали. Собрали ранее оговоренных сроков. Огромное спасибо за такой подход к клиентам!
Читать весь отзыв28.![]() 03.2023
03.2023
Екатерина
Заказывали в детскую кровать Пинетти вместе с матрасом. Все работы были выполнены в срок, монтаж осуществлялся аккуратно). Мы очень довольны результатом, а главное 7-ми летний ребенок может самост…
Читать весь отзыв09.02.2023
Олеся
Выражаю огромную благодарность компании ZYM Mebel. Мы заказывали шкаф-кровать-диван 3 в 1 трансформер. Остались очень довольны качеством и исполнением. Отдельная благодарность нашему дизайнеру — Алесе…
25. 08.2022
08.2022
Елена
Огромная благодарность команде. Ребята монтажники молодцы, аккуратно, точно и быстро. Алесе Самец — дизайнеру отдельное спасибо: всегда на связи, готова помочь в любое время). Сын в вос…
Читать весь отзыв13.02.2023
Антонина
Мы заказывали кровать-трансформер для квартиры студии! Остались очень довольны результатом сотрудничества с компанией Мебель-холл (Зум Мебель). От этапа прорисовки проекта с дизайнером Алесей (отдельн…
Читать весь отзыв10. 01.2023
01.2023
Виктория
Благодаря компании ЗУМ и нас дома теперь стоит шикарная шкаф-кровать. Это просто находка. Очень довольны, что решились выбрать не стандартный диван или кровать, а трансформер.
Читать весь отзывМеханизм шкаф-кровать трансформер в Энгельсе: 590-товаров: бесплатная доставка, скидка-35% [перейти]
Партнерская программаПомощь
Энгельс
Каталог
Каталог Товаров
Одежда и обувьОдежда и обувь
СтройматериалыСтройматериалы
Текстиль и кожаТекстиль и кожа
Здоровье и красотаЗдоровье и красота
Детские товарыДетские товары
Продукты и напиткиПродукты и напитки
ЭлектротехникаЭлектротехника
Дом и садДом и сад
Торговля и складТорговля и склад
ПромышленностьПромышленность
Мебель и интерьерМебель и интерьер
Все категории
ВходИзбранное
61 700
Трансформер шкаф кровать 1200*2000 вертикальная РФ102 ГН PUSH Тип товара: кровать—трансформер
ПОДРОБНЕЕМеханизм дивана трансформер для шкаф кровать РФ102 2000 Тип товара: кровать—трансформер
ПОДРОБНЕЕ65 290
Шкаф—кровать трансформер Джули 27 Производитель: Бэст-Мебель, Тип товара: кровать—трансформер
ПОДРОБНЕЕ11 300
Механизм дивана трансформер Luxe для шкаф кровать РФ102 1200*2000 Тип товара: кровать—трансформер
ПОДРОБНЕЕ71 350
Шкаф—кровать трансформер Фанки Тип товара: кровать—трансформер, Число мест: двуспальная
ПОДРОБНЕЕ78 030
Шкаф—кровать трансформер Комбинатор Тип товара: кровать—трансформер, Конструкция: изголовье
ПОДРОБНЕЕМеханизм дивана трансформер для шкаф кровать РФ102 1800*2000 Тип товара: кровать—трансформер
ПОДРОБНЕЕ65 800
Трансформер шкаф кровать 1400*2000 РФ102 полка нога PUSH Тип товара: кровать—трансформер
ПОДРОБНЕЕМеханизм дивана трансформер для шкаф кровать РФ102 1200*2000 Тип товара: кровать—трансформер
ПОДРОБНЕЕ59 700
Трансформер шкаф кровать РФ102ПН 900*2000 PUSH Тип товара: кровать—трансформер
ПОДРОБНЕЕ Механизм шкафа-кроватиМеханизмы шкаф-кроватьМеханизм дивана трансформер для шкаф кровать РФ102 900*2000 Тип товара: кровать—трансформер
ПОДРОБНЕЕ10 800
Механизм дивана трансформер Luxe для шкаф кровать РФ102 900*2000 Тип товара: кровать—трансформер
ПОДРОБНЕЕ13 600
Механизм дивана трансформер Luxe для шкаф кровать РФ102 1800*2000 Тип товара: кровать—трансформер
ПОДРОБНЕЕ60 800
Трансформер шкаф кровать 900*2000 РФ102 полка нога PUSH Тип товара: кровать—трансформер
ПОДРОБНЕЕ60 800
Трансформер шкаф кровать 1200*2000 РФ102 полка нога PUSH Тип товара: кровать—трансформер
ПОДРОБНЕЕ45 000
Механизм двуспальной горизонтальной шкаф—кровати 1600*2000 РФ108 с диваном Тип товара: кровать,
ПОДРОБНЕЕ30 800
Механизм шкаф кровать РФ102 полка нога (900,1200,1400, 1600) PUSH Тип товара: кровать—трансформер
ПОДРОБНЕЕ32 000
Механизм шкаф кровать 1600*2000 со столом РФ103ГН PUSH Тип товара: кровать—трансформер, Ширина
ПОДРОБНЕЕ11 500
Механизм дивана трансформер Luxe для шкаф кровать РФ102 1400*2000 Тип товара: кровать—трансформер
ПОДРОБНЕЕ32 700
Механизм шкаф кровать диван РФ102 (900,1200,1400,1600, 1800) PUSH ГН Тип товара: кровать—трансформер
ПОДРОБНЕЕ31 000
Механизм шкаф кровать 1400*2000 со столом РФ103 PUSH Тип товара: кровать—трансформер, Ширина
ПОДРОБНЕЕ69 800
Трансформер шкаф кровать 1600*2000 РФ102 полка нога PUSH Тип товара: кровать—трансформер
ПОДРОБНЕЕ57 730
Шкаф—кровать трансформер Роббинс Тип товара: кровать—трансформер
ПОДРОБНЕЕ83 660
Шкаф—кровать трансформер Ватсон Тип товара: кровать—трансформер, Число мест: двуспальная
ПОДРОБНЕЕ34 766
Шкаф—кровать трансформер STUDIO140 Производитель: МакС, Тип товара: кровать—трансформер, Материал
ПОДРОБНЕЕ11 800
Механизм дивана трансформер Luxe для шкаф кровать РФ102 1600*2000 Тип товара: кровать—трансформер
ПОДРОБНЕЕ-35%
73 570
113525
Шкаф—кровать трансформер Фиона 34 Производитель: Бэст-Мебель, Тип товара: кровать—трансформер
ПОДРОБНЕЕ76 010
Шкаф—кровать трансформер Меган 121 Тип товара: кровать—трансформер
ПОДРОБНЕЕ2 страница из 18
Механизм шкаф-кровать трансформер
Все, что вам нужно знать о «Внимании» и «Трансформерах» — Углубленное понимание — Часть 1 | Арджун Саркар
Внимание, внимание к себе, внимание нескольких голов и трансформеры
Опубликовано в·
12 мин чтения·
15 февраля 2022 г. Рисунок 1. Источник: Фото Арсения Тогулева на Unsplash
Рисунок 1. Источник: Фото Арсения Тогулева на UnsplashЭто длинная статья, в которой рассказывается почти обо всем, что нужно знать о механизме внимания, включая самовнимание, запрос, ключи, значения, внимание с несколькими головками, внимание с несколькими головками в масках и преобразователи, включая некоторые подробности о BERT и GPT. Поэтому я разделил статью на две части. В этой статье я расскажу обо всех блоках Attention, а в следующей истории я углублюсь в архитектуру Transformer Network.
Содержание:
- Проблемы, связанные с RNN, и как модели Transformer могут помочь преодолеть эти проблемы
- Механизм внимания
2.1 Самостоятельное внимание
2.2 Запрос, ключ и значения
2.3 Нейросетевое представление внимания
2.4 Мультиголовное внимание
3. Трансформаторы (продолжение в следующей статье)
Введение
компьютерное зрение, чтобы попытаться понять, на что смотрит нейронная сеть, делая прогноз. Это был один из первых шагов, чтобы попытаться понять результаты сверточных нейронных сетей (CNN). В 2015 году внимание было впервые использовано в обработке естественного языка (NLP) в выравниваемом машинном переводе. Наконец, в 2017 году механизм внимания был использован в сетях Transformer для языкового моделирования. С тех пор трансформеры превзошли по точности предсказания рекуррентные нейронные сети (RNN) и стали самыми современными задачами НЛП.
Это был один из первых шагов, чтобы попытаться понять результаты сверточных нейронных сетей (CNN). В 2015 году внимание было впервые использовано в обработке естественного языка (NLP) в выравниваемом машинном переводе. Наконец, в 2017 году механизм внимания был использован в сетях Transformer для языкового моделирования. С тех пор трансформеры превзошли по точности предсказания рекуррентные нейронные сети (RNN) и стали самыми современными задачами НЛП.
1.1 Проблема RNN 1 — Возникают проблемы с зависимостями дальнего действия. RNN плохо работают с длинными текстовыми документами.
Трансформаторное решение — Трансформаторные сети почти исключительно используют блоки внимания. Внимание помогает установить связь между любыми частями последовательности, поэтому дальние зависимости больше не проблема. С трансформаторами долгосрочные зависимости имеют такую же вероятность быть принятыми во внимание, как и любые другие краткосрочные зависимости.
1.2. RNN проблема 2 — Страдает исчезновением градиента и взрывом градиента.
Transformer Solution — исчезновение или взрыв градиента практически отсутствуют. В сетях Transformer вся последовательность обучается одновременно, и для ее построения добавляется всего несколько слоев. Таким образом, исчезновение градиента или взрыв редко являются проблемой.
1.3. Проблема RNN 3 — RNN требуют больших шагов обучения для достижения локального/глобального минимума. RNN можно представить как развёрнутую очень глубокую сеть. Размер сети зависит от длины последовательности. Это порождает множество параметров, и большинство из этих параметров взаимосвязаны друг с другом. В результате оптимизация требует более длительного обучения и большого количества шагов.
Transformer Solution — требует меньше шагов для обучения, чем RNN.
1.4. Проблема RNN 4 — RNN не допускают параллельных вычислений.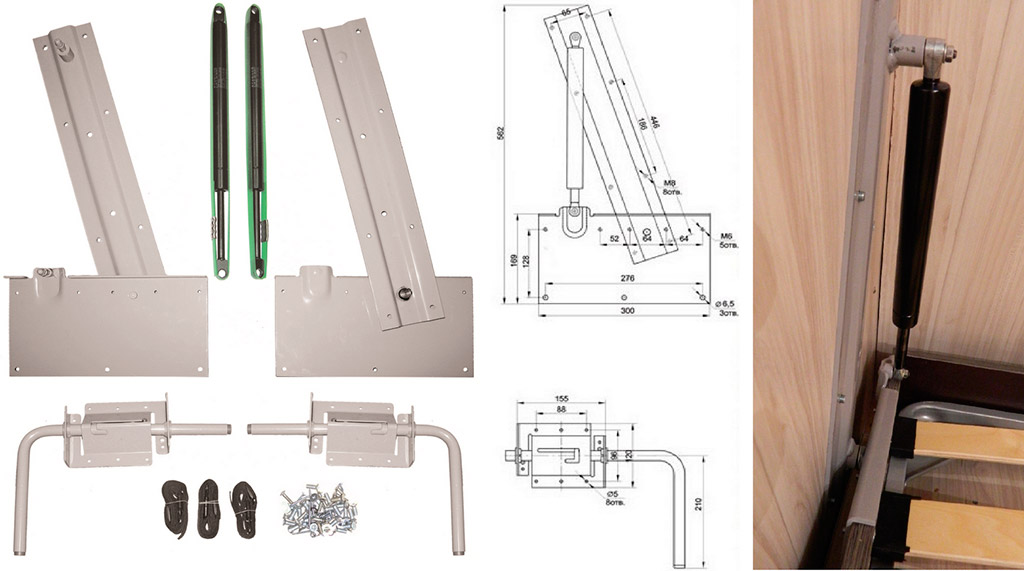 Графические процессоры помогают добиться параллельных вычислений. Но RNN работают как модели последовательности, то есть все вычисления в сети происходят последовательно и не могут быть распараллелены.
Графические процессоры помогают добиться параллельных вычислений. Но RNN работают как модели последовательности, то есть все вычисления в сети происходят последовательно и не могут быть распараллелены.
Трансформаторное решение — Отсутствие повторения в трансформаторных сетях позволяет выполнять параллельные вычисления. Таким образом, вычисления могут выполняться параллельно для каждого шага.
2.1 Внимание к себе
Рисунок 2. Пример для объяснения внимания к себе (Источник: изображение создано автором) Рассмотрим предложение — « Барк очень милый, и он — собака ». В этом предложении 9 слов или токенов. Если мы просто рассмотрим слово «он» в предложении, мы увидим, что «и» и «есть» — это два слова, которые находятся в непосредственной близости от него. Но эти слова не придают слову «он» никакого контекста. Скорее слова «лай» и «собака» гораздо больше связаны с «он» в предложении. Из этого мы понимаем, что близость не всегда имеет значение, но контекст в предложении более важен.
Когда это предложение загружается в компьютер, он рассматривает каждое слово как токен t, , и каждый токен имеет вложение слова V . Но эти вложения слов не имеют контекста. Таким образом, идея состоит в том, чтобы применить какое-то взвешивание или сходство для получения конечного вложения слов Y , которое имеет больше контекста, чем исходное вложение V .
В пространстве вложения похожие слова появляются ближе друг к другу или имеют аналогичные вложения. Например, слово «король» будет больше связано со словом «королева» и «королевская власть», чем со словом «зебра». Точно так же «зебра» будет больше связана с «лошадью» и «полосами», чем со словом «эмоция». Чтобы узнать больше о встраивании пространства, посмотрите это видео Эндрю Нг (NLP и Word Embeddings).
Таким образом, интуитивно, если слово «король» появляется в начале предложения, а слово «королева» — в конце предложения, они должны обеспечить друг другу лучший контекст. Мы используем эту идею, чтобы найти векторы весов W, путем умножения (точечный продукт) вложений слов вместе, чтобы получить больше контекста. Итак, в предложении Барк очень милый, и он — собака, вместо того, чтобы использовать вложения слов как есть, мы умножаем вложения каждого слова друг на друга. Рисунок 3 должен лучше это проиллюстрировать.
Мы используем эту идею, чтобы найти векторы весов W, путем умножения (точечный продукт) вложений слов вместе, чтобы получить больше контекста. Итак, в предложении Барк очень милый, и он — собака, вместо того, чтобы использовать вложения слов как есть, мы умножаем вложения каждого слова друг на друга. Рисунок 3 должен лучше это проиллюстрировать.
Как мы видим на рисунке 3, мы сначала находим веса, умножая (точечный продукт) начальное вложение первого слова на вложение всех остальных слов в предложение. Эти веса (от W11 до W19) также нормированы, чтобы иметь сумму 1. Затем эти веса умножаются на начальные вложения всех слов в предложении.
W11 V1 + W12 V2 + …. W19 V9 = Y1
W11 — W19 — все веса, имеющие контекст первого слова V1. Поэтому, когда мы умножаем эти веса на каждое слово, мы, по сути, перевешиваем все остальные слова по отношению к первому слову.![]() Таким образом, в некотором смысле слово « Лай » теперь больше похоже на слова « собака » и « милый », а не на слово, которое идет сразу после него. И это, в некотором смысле, дает некоторый контекст.
Таким образом, в некотором смысле слово « Лай » теперь больше похоже на слова « собака » и « милый », а не на слово, которое идет сразу после него. И это, в некотором смысле, дает некоторый контекст.
Это повторяется для всех слов, так что каждое слово получает некоторый контекст от каждого другого слова в предложении.
Рисунок 4. Графическое представление вышеуказанных шагов (Источник: изображение создано автором)Рисунок 4 дает лучшее понимание вышеуказанных шагов для получения Y1 с использованием графической диаграммы.
Что здесь интересно, так это то, что веса не тренируются, порядок или близость слов не влияют друг на друга. Также процесс не имеет зависимости от длины предложения, то есть больше или меньше слов в предложении не имеет значения. Этот подход добавления некоторого контекста к словам в предложении известен как Самостоятельное внимание .
2.2 Запрос, ключ и значения
Проблема с самостоятельным вниманием заключается в том, что ничего не обучается. Но, может быть, если мы добавим некоторые обучаемые параметры, сеть сможет изучить некоторые шаблоны, которые дадут гораздо лучший контекст. Этот обучаемый параметр может быть матрицей, значения которой обучаются. Так появилась идея запроса, ключа и значений.
Но, может быть, если мы добавим некоторые обучаемые параметры, сеть сможет изучить некоторые шаблоны, которые дадут гораздо лучший контекст. Этот обучаемый параметр может быть матрицей, значения которой обучаются. Так появилась идея запроса, ключа и значений.
Давайте снова рассмотрим предыдущее предложение — « Барк очень милый, и он собака ». На рис. 4 при самоконтроле мы видим, что начальные вложения слов ( V ) используются 3 раза. 1-й как скалярное произведение между первым вложением слова и всеми другими словами (включая само себя, 2-е) в предложении, чтобы получить веса, а затем умножить их снова (3-й раз) на веса, чтобы получить окончательное вложение с контекстом. Эти 3 вхождения буквы V можно заменить тремя терминами Query , Keys и Values .
Допустим, мы хотим сделать все слова похожими относительно первого слова V1. Затем мы отправляем V1 в качестве слова запроса. Затем это слово запроса произведет скалярное произведение всех слов в предложении (от V1 до V9).![]() ) — а это Ключи. Таким образом, комбинация Запроса и Ключей дает нам веса. Затем эти веса снова умножаются на все слова (от V1 до V9), которые действуют как значения. Там у нас есть запрос, ключи и значения. Если у вас все еще есть какие-то сомнения, рисунок 5 должен развеять их.
) — а это Ключи. Таким образом, комбинация Запроса и Ключей дает нам веса. Затем эти веса снова умножаются на все слова (от V1 до V9), которые действуют как значения. Там у нас есть запрос, ключи и значения. Если у вас все еще есть какие-то сомнения, рисунок 5 должен развеять их.
Но подождите, мы еще не добавили матрицу, которую можно обучить. Это довольно просто. Мы знаем, что если вектор в форме 1 x k умножить на матрицу в форме k x k, мы получим вектор в форме 1 x k на выходе. Имея это в виду, давайте просто умножим каждую клавишу от V1 до V10 (каждая из форм 1 x k) на матрицу Mk (матрица клавиш) формы k x k. Точно так же вектор запроса умножается на матрицу Mq (матрица запроса), а векторы значений умножаются на матрицу значений Mv. Все значения в этих матрицах Mk, Mq и Mv теперь могут быть обучены нейронной сетью и давать гораздо лучший контекст, чем просто использование собственного внимания. Опять же, для лучшего понимания, на рис. 6 показано графическое представление того, что я только что объяснил.
Опять же, для лучшего понимания, на рис. 6 показано графическое представление того, что я только что объяснил.
Теперь, когда мы интуитивно понимаем ключи, запросы и значения, давайте посмотрим на анализ базы данных и официальные шаги и формулы, лежащие в основе Attention.
Давайте попробуем понять механизм Attention на примере базы данных. Итак, в базе данных, если мы хотим получить некоторое значение v i на основе запроса q и ключа k i, могут быть выполнены некоторые операции, в которых мы можем использовать запрос для определения ключа, соответствующего определенному значению. Внимание можно рассматривать как процесс, аналогичный этой технике базы данных, но в более вероятностной манере. Это показано на рисунке ниже.
На рис. 7 показаны этапы поиска данных в базе данных. Предположим, мы отправляем запрос в базу данных, некоторые операции будут выяснять, какой ключ в базе больше всего похож на запрос.![]() Как только ключ будет найден, он отправит значение, соответствующее этому ключу, в качестве вывода. На рисунке операция обнаруживает, что Запрос больше всего похож на Ключ 5, и, следовательно, дает нам значение 5 в качестве вывода.
Как только ключ будет найден, он отправит значение, соответствующее этому ключу, в качестве вывода. На рисунке операция обнаруживает, что Запрос больше всего похож на Ключ 5, и, следовательно, дает нам значение 5 в качестве вывода.
Механизм «Внимание» представляет собой нейронную архитектуру, которая имитирует этот процесс поиска.
- Механизм внимания измеряет сходство между запросом q и каждым ключом-значением k i.
- Это сходство возвращает вес для каждого значения ключа.
- Наконец, на выходе получается взвешенная комбинация всех значений в нашей базе данных.
Единственная разница между поиском в базе данных и вниманием состоит в том, что при поиске в базе данных мы получаем только одно значение в качестве входных данных, а здесь мы получаем взвешенную комбинацию значений. В механизме внимания, если запрос больше всего похож, скажем, на ключ 1 и ключ 4, то оба этих ключа получат наибольший вес, а на выходе будет комбинация значений 1 и 4.
На рис. 8 показаны шаги, необходимые для получения конечного значения внимания из запроса, ключей и значений. Каждый шаг подробно объясняется ниже.
(Ключевые значения k являются векторами, значения сходства S являются скалярами, значения веса (softmax) a являются скалярами, а значения V являются векторами)
Рисунок 8. Шаги для достижения Аттена Значение (Источник: изображение создано автором)Шаг 1.
Шаг 1 содержит ключи, запрос и соответствующие меры сходства. Запрос q влияет на сходство. У нас есть запрос и ключи, и мы вычисляем сходство. Подобие есть некоторая функция запроса q и ключей k . И запрос, и ключи являются некоторыми векторами встраивания. Сходство S можно рассчитать с помощью различных методов, как показано на рис. 9.
Рис. 9. Способы расчета схожести (Источник: изображение создано автором) Сходство может быть простым скалярным произведением запроса и ключа. Его можно масштабировать скалярным произведением, где скалярное произведение q и k, делится на квадратный корень из размерности каждого ключа, d. Это два наиболее часто используемых метода поиска сходства.
Его можно масштабировать скалярным произведением, где скалярное произведение q и k, делится на квадратный корень из размерности каждого ключа, d. Это два наиболее часто используемых метода поиска сходства.
Часто запрос проецируется в новое пространство с использованием весовой матрицы W, , а затем производится скалярное произведение с ключом k . Методы ядра также могут использоваться в качестве подобия.
Шаг 2.
Шаг 2 — нахождение весов и . Это делается с помощью ‘ СофтМакс ’. Формула показана ниже. (exp является экспоненциальным)
Сходства связаны с весами, как полносвязный слой.
Шаг 3.
Шаг 3 представляет собой взвешенную комбинацию результатов softmax ( a ) с соответствующими значениями ( V ). 1-е значение a умножается на первое значение V и затем суммируется с произведением 2-го значения a на 2-е значение Values В и так далее. Конечным результатом, который мы получаем, является желаемое значение внимания.
Конечным результатом, который мы получаем, является желаемое значение внимания.
Итог трех шагов:
W с помощью запроса q и ключей k мы получаем значение внимания, которое является взвешенной суммой/линейной комбинацией значений V, 9004 3, а веса исходят из некоторого сходства между запросом и ключами.
2.3 Нейросетевое представление внимания
Рисунок 10. Представление блока внимания нейронной сетью (Источник: изображение создано автором) На рисунке 10 показано представление нейронной сети блока внимания. Вложения слов сначала передаются в некоторые линейные слои. Эти линейные слои не имеют термина «смещение» и, следовательно, представляют собой не что иное, как умножение матриц. Один из этих слоев обозначается как «ключи», другой — как «запросы», а последний — как «значения». Если матричное умножение выполняется между ключами и запросами, а затем нормализуется, мы получаем веса. Затем эти веса умножаются на значения и суммируются, чтобы получить окончательный вектор внимания. Этот блок теперь можно использовать в нейронной сети, он известен как блок «Внимание». Можно добавить несколько таких блоков внимания, чтобы обеспечить больше контекста. И самое приятное то, что мы можем получить обратное распространение градиента для обновления блока внимания (веса ключей, запросов, значений).
Этот блок теперь можно использовать в нейронной сети, он известен как блок «Внимание». Можно добавить несколько таких блоков внимания, чтобы обеспечить больше контекста. И самое приятное то, что мы можем получить обратное распространение градиента для обновления блока внимания (веса ключей, запросов, значений).
2.4 Внимание с несколькими головками
Чтобы преодолеть некоторые ловушки, связанные с использованием одного внимания, используется внимание с несколькими головками. Вернемся к предложению — « Барк очень милый, и он — собака ». Здесь, если мы возьмем слово «собака», грамматически мы понимаем, что слова «лай», «милый» и «он» должны иметь какое-то значение или отношение к слову «собака». Эти слова говорят о том, что собаку зовут Барк, это кобель, и что он милый пес. Только один механизм внимания может быть не в состоянии правильно идентифицировать эти три слова как релевантные слову «собака», и мы можем сказать, что здесь лучше использовать три внимания, чтобы обозначить три слова со словом «собака». Это снижает нагрузку на одно внимание при поиске всех значимых слов, а также увеличивает шансы легко найти более релевантные слова.
Это снижает нагрузку на одно внимание при поиске всех значимых слов, а также увеличивает шансы легко найти более релевантные слова.
Итак, давайте добавим больше линейных слоев в виде ключей, запросов и значений. Эти линейные слои тренируются параллельно и имеют независимые веса по отношению друг к другу. Итак, теперь каждое из значений, ключей и запросов дает нам три выхода вместо одного. Эти 3 ключа и запроса теперь дают три разных веса. Эти три веса затем с матричным умножением на три значения, чтобы дать три множественных выхода. Эти три блока внимания, наконец, объединяются, чтобы дать один окончательный вывод внимания. Это представление показано на рисунке 11.
Рисунок 11. Мультиголовное внимание с 3 линейными слоями (Источник: изображение создано автором) Но 3 — это просто случайное число, которое мы выбрали. В реальном сценарии это может быть любое количество линейных слоев, и они называются головками ( h ). То есть может быть ч линейных слоев, дающих ч выходных данных внимания, которые затем объединяются вместе. И именно поэтому это называется многоголовым вниманием (множественными головками). Более простой вариант рисунка 11, но с h количество головок показано на рисунке 12.
И именно поэтому это называется многоголовым вниманием (множественными головками). Более простой вариант рисунка 11, но с h количество головок показано на рисунке 12.
Теперь, когда мы понимаем механизм и идею, лежащие в основе внимания, запроса, ключей, значений и внимания с несколькими головками, мы рассмотрели все важные строительные блоки сети Transformer. В следующем рассказе я расскажу о том, как все эти блоки складываются вместе, чтобы сформировать Transformer Network, а также расскажу о некоторых сетях на основе Transformers, таких как BERT и GPT.
Ссылки:
Ашиш Васвани, Ноам Шазир, Ники Пармар, Якоб Ушкорейт, Ллион Джонс, Эйдан Н. Гомес, Лукаш Кайзер и Илья Полосухин. 2017. Внимание — это все, что вам нужно. В материалах 31-й Международной конференции по системам обработки нейронной информации (NIPS’17). Curran Associates Inc., Ред-Хук, Нью-Йорк, США, 6000–6010.![]()
Внимание и модели-трансформеры. «Внимание — это все, что вам нужно» — это… | Хелен Корчак
Простое объяснение сложного алгоритма
Опубликовано в·
8 минут чтения·
16 ноября 2020 г. (Изображение автора)знаменательная статья, в которой предлагался совершенно новый тип модели — Трансформер. В настоящее время модель Transformer широко распространена в сфере машинного обучения, но ее алгоритм довольно сложен, и его трудно понять. Надеюсь, этот пост в блоге даст вам больше ясности по этому поводу.
Так что же означают все эти разноцветные прямоугольники на изображении ниже? В целом модель Transformer основана на архитектуре кодер-декодер. Кодер — серый прямоугольник слева, декодер — справа. И кодер, и декодер состоят из двух и трех подуровней соответственно: мульти-головное само-внимание , полностью подключенная сеть прямой связи и — в случае декодера — кодер-декодер само-внимание (названное мульти-головным вниманием на визуализации ниже).
Что не так ясно видно на рисунке, так это то, что Transformer на самом деле объединяет несколько кодеров и декодеров (что на изображении обозначено Nx, т. е. кодеры и декодеры расположены друг над другом n раза). Это означает, что выходные данные одного кодировщика используются в качестве входных данных для следующего кодирующего устройства, а выходные данные одного декодера используются в качестве входных данных для следующего декодера.
Что нового в Transformer, так это не его архитектура кодер-декодер, а отказ от традиционно используемых рекуррентных слоев. Вместо этого он полностью полагается на внимание к себе.
Так что же такое внимание к себе? Короче говоря, это способ модели осмыслить входные данные, которые она получает.
Одна из проблем рекуррентных моделей заключается в том, что долгосрочные зависимости (внутри последовательности или между несколькими последовательностями) часто теряются. То есть, если слово в начале последовательности имеет значение для слова в конце последовательности, модель могла бы забыть первое слово, как только оно дошло до последнего слова. Не такие уж умные эти RNN, не так ли? 😉 Модели-трансформеры используют другую стратегию для запоминания всей последовательности: внимание к себе!
То есть, если слово в начале последовательности имеет значение для слова в конце последовательности, модель могла бы забыть первое слово, как только оно дошло до последнего слова. Не такие уж умные эти RNN, не так ли? 😉 Модели-трансформеры используют другую стратегию для запоминания всей последовательности: внимание к себе!
В слое само-внимания ввод x (представленный в виде вектора) превращается в вектор z через три репрезентативных вектора ввода: q(ueries), k(eys) и v(alues). Они используются для расчета оценки, которая показывает, сколько внимания этот конкретный ввод должен уделять другим элементам в данной последовательности.
То, что я только что расплывчато выразил словами, может быть определено следующей формулой гораздо точнее:
(Изображение автора) Поскольку формулы не всегда очень интуитивны, пошаговая визуализация расчета должна немного прояснить ситуацию.
Допустим, мы хотим вычислить самовнимания для слова «пушистый» в последовательности «пушистые блины». Во-первых, мы берем входной вектор x1 (представляющий слово «пушистый») и умножаем его на три разные весовые матрицы Wq, Wk и Wv (которые постоянно обновляются во время обучения), чтобы получить три разных вектора: q1, k1 и v1. То же самое делается для входного вектора x2 (обозначает слово «блинчики»). Теперь у нас есть запрос, ключ и вектор значений для обоих слов.
Запрос — это представление слова, для которого мы хотим вычислить самовнимание. Итак, поскольку мы хотим привлечь внимание к «пушистику», мы рассматриваем только его запрос, а не запрос «блинчиков». Как только мы закончим вычислять само-внимание для «пушистика», мы также можем отбросить его вектор запроса.
Ключ представляет собой представление каждого слова в последовательности и используется для сопоставления с запросом слова, для которого мы в настоящее время хотим вычислить самовнимание.
Значение — это фактическое представление каждого слова в последовательности, представление, которое нас действительно интересует. Умножение запроса и ключа дает нам оценку, которая говорит нам, какой вес получает каждое значение (и, следовательно, соответствующее ему слово) в векторе само-внимания. Обратите внимание, что значение не умножается напрямую на оценку, но сначала оценки делятся на квадратный корень из dk , размерность ключевого вектора и применяется softmax.
Результатом этих вычислений является один вектор для каждого слова. В качестве последнего шага эти два вектора суммируются, и вуаля, у нас есть внимание к слову «пушистый».
Самостоятельное внимание к слову «его». Строки показывают, сколько внимания слово «его» уделяет другим словам в последовательности. (Изображение автора) Возможно, вы заметили, что он называется многоголовым вниманием к себе. Это связано с тем, что описанный выше процесс выполняется несколько раз с разными весовыми матрицами, а это означает, что мы получаем несколько векторов (называемых решками в приведенных ниже формулах). Затем эти головки объединяются и умножаются на весовую матрицу Wo. Это означает, что каждая головка получает разную информацию о заданной последовательности и что в конце эти знания объединяются.
Затем эти головки объединяются и умножаются на весовую матрицу Wo. Это означает, что каждая головка получает разную информацию о заданной последовательности и что в конце эти знания объединяются.
Пока что я не упомянул самое главное: все эти вычисления можно распараллелить . Почему это так важно? Давайте сначала посмотрим на RNN. Им нужно обрабатывать последовательные данные по порядку, т.е. каждое слово последовательности передается в модель одно за другим, одно за другим. Однако модели-трансформеры могут обрабатывать все входы одновременно. И это делает эти модели невероятно быстрыми, позволяя обучать их на огромных объемах данных. Теперь вы удивляетесь, как Трансформер узнает правильный порядок предложения, если он получает его все сразу? Я объясню это в разделе о позиционных кодировках ниже.
Как мы видели на самом первом изображении, показывающем архитектуру Transformer, уровни внутреннего внимания интегрированы как в кодировщик, так и в декодер. Который только что посмотрел, как выглядит само-внимание в энкодере. Декодер, однако, использует так называемое маскированное многоголовое самовнимание . Это означает, что некоторые позиции на входе декодера маскируются и поэтому игнорируются уровнем внутреннего внимания. Почему они маскируются? При предсказании следующего слова предложения декодер не должен знать, какое слово следует за предсказанным словом. Вместо этого декодеру должны быть известны только слова до текущих позиций. В конце концов, при фактическом использовании модели для получения реальных предсказаний следующего слова декодер также не может видеть будущие позиции. Таким образом, маскируя их во время обучения, мы не позволяем декодеру обманывать.
Который только что посмотрел, как выглядит само-внимание в энкодере. Декодер, однако, использует так называемое маскированное многоголовое самовнимание . Это означает, что некоторые позиции на входе декодера маскируются и поэтому игнорируются уровнем внутреннего внимания. Почему они маскируются? При предсказании следующего слова предложения декодер не должен знать, какое слово следует за предсказанным словом. Вместо этого декодеру должны быть известны только слова до текущих позиций. В конце концов, при фактическом использовании модели для получения реальных предсказаний следующего слова декодер также не может видеть будущие позиции. Таким образом, маскируя их во время обучения, мы не позволяем декодеру обманывать.
Один важный аспект модели все еще отсутствует.![]() Как информация поступает от кодировщика к декодеру? Именно для этого и предназначен слой внутреннего внимания кодировщика-декодера . Этот уровень работает очень похоже на уровень самоконтроля в кодировщике. Однако вектор запроса исходит из предыдущего замаскированного слоя внутреннего внимания, а вектор ключа и значения исходит из выходных данных самого верхнего кодировщика. Это позволяет декодеру учитывать все позиции во входной последовательности кодера.
Как информация поступает от кодировщика к декодеру? Именно для этого и предназначен слой внутреннего внимания кодировщика-декодера . Этот уровень работает очень похоже на уровень самоконтроля в кодировщике. Однако вектор запроса исходит из предыдущего замаскированного слоя внутреннего внимания, а вектор ключа и значения исходит из выходных данных самого верхнего кодировщика. Это позволяет декодеру учитывать все позиции во входной последовательности кодера.
Итак, теперь мы знаем, что делают слои внутреннего внимания в каждом кодере и декодере. Это оставляет нас с другим подуровнем, о котором мы не говорили: полностью подключенными сетями прямой связи. Они дополнительно обрабатывают выходные данные уровня внутреннего внимания, прежде чем передать их следующему кодеру или декодеру.
(Изображение автора) Каждая сеть прямой связи состоит из двух линейных слоев с функцией ReLU между ними. Веса и смещения W1, W2, b1 и b2 одинаковы для разных позиций в последовательности, но различаются в каждом кодере и декодере.
Как мы уже говорили, модель Transformer может обрабатывать все слова в последовательности параллельно. Однако при этом теряется некоторая важная информация: позиция слов в последовательности . Чтобы сохранить эту информацию, положение и порядок слов должны быть явно указаны в модели. Это делается с помощью позиционного кодирования. Эти позиционные кодировки являются векторами той же размерности, что и входной вектор, и вычисляются с использованием функции синуса и косинуса. Для объединения информации входного вектора и позиционного кодирования их просто суммируют.
Для более подробного объяснения того, как именно работают позиционные кодировки, я рекомендую эту статью здесь.
Одним из небольших, но важных аспектов моделей Transformer является нормализация уровня, которая выполняется после каждого подуровня в каждом кодере и декодере.
(Изображение автора) Сначала суммируются вход и выход соответствующего уровня кодировщика или декодера. Это означает, что в самом нижнем слое суммируются входной вектор X и выходной вектор Z1; во втором слое входной вектор Z1 и выходной вектор Z2 и так далее. Затем суммированный вектор нормализуется со средним значением, равным нулю, и единичной дисперсии. Это предотвращает слишком сильные колебания диапазона значений в данном слое и, таким образом, позволяет модели быстрее сходиться.
Это означает, что в самом нижнем слое суммируются входной вектор X и выходной вектор Z1; во втором слое входной вектор Z1 и выходной вектор Z2 и так далее. Затем суммированный вектор нормализуется со средним значением, равным нулю, и единичной дисперсии. Это предотвращает слишком сильные колебания диапазона значений в данном слое и, таким образом, позволяет модели быстрее сходиться.
Для более подробного объяснения нормализации слоев я рекомендую эту статью здесь.
Наконец, чтобы получить выходные предсказания, нам каким-то образом нужно преобразовать выходной вектор последнего декодера в слова. Итак, мы сначала передаем выходной вектор в полносвязный линейный слой и получаем логитс-вектор размера словаря. Затем мы применяем функцию softmax к этому вектору, чтобы получить оценку вероятности для каждого слова в словаре. Затем мы выбрали слово с максимальной вероятностью в качестве нашего прогноза.
Очки вероятности для предсказания следующего слова «Маленькая собачка ___».Модель «Трансформер» — это новый тип модели кодировщика-декодера, который использует внутреннее внимание для понимания языковых последовательностей. Это позволяет выполнять параллельную обработку и, таким образом, делает ее намного быстрее, чем любая другая модель с такой же производительностью. Таким образом, они проложили путь для современных языковых моделей (таких как BERT и GPT), а в последнее время и для моделей генерации изображений.
Каталожные номера [1] А. Васвани, Н. Шазир, Н. Пармар, Дж. Ушкорейт, Л. Джонс, А. Н. Гомес, Л. Кайзер и И. Полосухин, Внимание — это все, что вам нужно (2017), NIPS’17: Материалы 31-й Международной конференции по системам обработки нейронной информации
[2] А. Каземнежад, Преобразование er Architecture: The Positional Encoding (2019), Блог Amirhossein Kazemnejad
[3] L. Mao, Объяснение нормализации слоев (2019), Журнал учета Lei Mao
Кредиты
Особая благодарность Филипу Попиену за предложения и исправления к этой статье.![]()